





April 21, 2026
By Brian McDonald
Americas CTO Office, Ciena
AI 인프라가 새로운 국면에 접어들고 있습니다. 에이전트형 AI가 CPU에 더 많은 오케스트레이션, 메모리 처리, 도구 실행을 요구하고 있기에, 네트워크는 수동 상호 연결에서 분산된 AI 작업 흐름을 지원하는 프로그래밍 가능한 고용량 인프라로 진화해야만 합니다. Ciena의 Brian McDonald에 대한 자세한 정보는 아래에서 참조하세요.
지난 10년간 대부분 AI 인프라 성장 내러티브는 더 많은 GPU, 더 빠른 GPU, 더 큰 GPU 클러스터에 집중하는 단면적인 양상을 보였습니다. 서비스 공급자는 이를 연결하는 네트워크를 구축 및 확장했고 대규모 모델 학습의 시대에는 그것이 적절한 인프라 구조였습니다. 하지만 차세대 가속기가 아닌 CPU의 르네상스가 시작되자 조용한 구조적 변화가 일어나고 있습니다. CPU의 르네상스는 중요한 사실을 알려줍니다. AI는 중앙 집중식 학습 위주의 작업 부하를 넘어서 분산형 오케스트레이션 집약적 작업 부하로 넘어가고 있으며 네트워크의 역할은 더 이상 단순히 컴퓨팅 인프라를 연결해 주는 데 그치지 않습니다. 오히려 그 일부가 되어 가고 있습니다.
2026년 변곡점: 'GPU 전용' 내러티브를 넘어서
2024년을 떠올려 보세요. 업계가 지속적인 사전 학습 골드러시와 점점 더 확장되는 추론의 새 시대를 모두 지원하도록 발전하면서 AI 인프라도 토폴로지 간소화를 거치게 되었습니다. 과거에는 대용량 데이터를 처리하기 위해 학습 클러스터에 4:1의 고밀도 비율이 필요했지만 대규모 추론을 괴롭히던 'CPU 부담'을 제거하는 쪽으로 초점이 변했습니다. Google의 TPU v6e와 Meta의 Grand Teton과 같은 추론에 최적화된 맞춤형 구축 부분에서는 GPU:CPU 소켓 비율이 8:1로 바뀌었습니다.
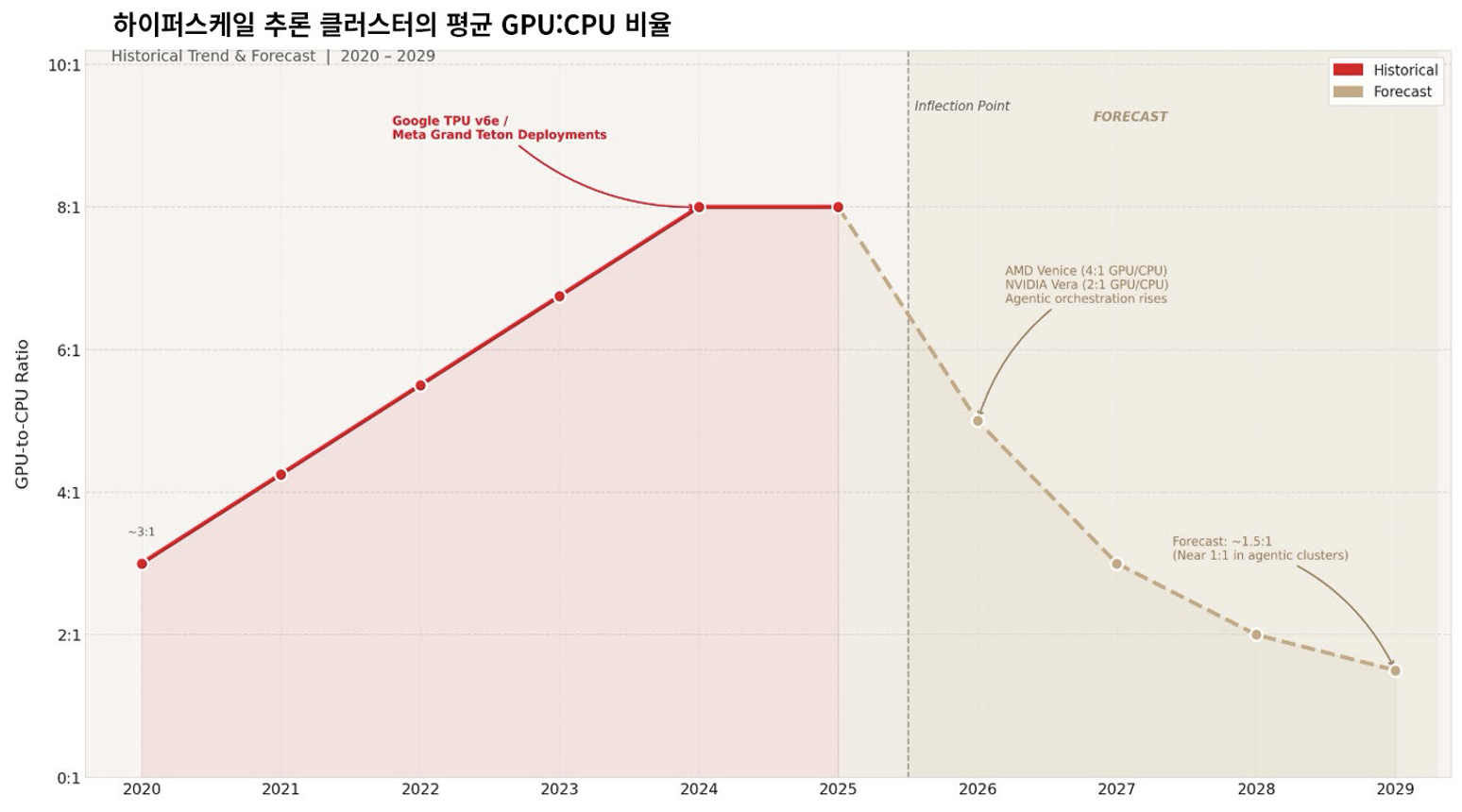
이 추세는 Google, Meta, NVIDIA, AMD에서 공개한 클러스터 사양을 Ciena에서 분석한 결과를 토대로 도출되었습니다.
오늘날의 미래 지향적 클러스터 설계는 코어 수가 높은 CPU를 컴퓨팅 계층 구조의 선두 역할로 다시 통합하는 방식이며 일각에서는 특정 클러스터의 GPU:CPU 비율이 1:1로 좁혀질 것으로 전망하고 있습니다. 특별히 강화 학습 환경, 도구 호출, 논리 제어, 문서 병합을 처리하도록 설계된 클러스터가 바로 여기에 속하는 경우입니다. 2026년의 특정 하드웨어 조합은 이러한 격차가 해소되고 있음을 보여줍니다.
- AMD Venice: 컴퓨팅 트레이당 CPU 1개와 MI455X GPU 4개.
- NVIDIA Vera: 슈퍼칩당 CPU 1개와 Rubin GPU 2개.
- Google TPU7x: 스케일업 장치당 CPU 1개와 TPU 칩 4개.
에이전트형 AI: 변화를 이끄는 기능
사용자 주도 생성형 AI에서 에이전트형 AI로의 전환이 이번에 하드웨어의 균형을 재편하는 가장 결정적인 단일 동력입니다. 생성형 AI는 프롬프트에 응답합니다. 에이전트형 AI는 목표를 이룹니다. 다단계 작업을 계획하고 실행하고 도구 및 외부 환경과 상호 작용하며 상황에 맞춰 지속적으로 조정합니다.
이러한 차이는 인프라에 심오한 영향을 미칩니다. 기존의 LLM 추론 호출은 비교적 독립적인 GPU 이벤트였습니다. 에이전트형 작업 흐름은 운영 체제와 유사하다고 볼 수 있습니다. 스레드를 생성하고 메모리를 관리하고 도구를 호출하고 API를 통해 상호 작용하며 강화 루프를 통해 반복하여 개선합니다.
토큰 경제 하나만 생각해 보겠습니다. 텍스트 토큰 50개로 구성된 단일 추론 요청은 에이전트 전체로 확산되면서 토큰 5만 개짜리 작업으로 진화할 수 있습니다. 이러한 1,000배 확장은 단순한 GPU 컴퓨팅의 향상뿐만 아니라 CPU에서 실행되는 도구와 오케스트레이션 로직의 향상을 의미합니다.
WAN 전파: 데이터 센터에서 광역 통신망으로
이 컴퓨팅 혁신은 DC(데이터 센터) 안에만 국한되지 않고 WAN(광역 통신망)으로 직접 전파되며 그 영향력은 상당히 큽니다.
AI 인프라가 중앙 집중식 실행에서 여러 시스템, 도메인, 데이터 소스 전반에 걸친 분산된 작업 흐름으로 전환되고 있습니다. 에이전트 작업 부하가 확장됨에 따라 불가피하게 여러 데이터 센터, 코로케이션 시설, 클라우드 지역으로 확산되면서 지속성, 폭발성, 양방향성을 지닌 새로운 유형의 트래픽을 생성하게 됩니다.
그 핵심 메커니즘은 분산 실행입니다. 에이전트 작업 흐름이 추론을 위한 GPU 노드와 오케스트레이션을 위한 CPU 노드 등 하드웨어에 최적화된 세부 단계로 나뉘면 상태와 메모리가 클러스터 전체와 그 너머로 지속적으로 공유되어야 합니다. 멀티 턴 에이전트 루프의 전체 상호 작용 내역을 저장하는 KV(Key-Value) 캐시는 여러 하드웨어 티어 사이에서 실행됨에 따라 다시 로드되고 오프로드되며 노드 전반에 공유되어야 합니다. 32K 토큰 컨텍스트 길이를 기준으로 추론 SLA 요구 사항을 충족하는 KV 캐시 전송을 위한 실질적인 최소 링크 용량은 200~400Gbps 정도인 것으로 산출됩니다.
그럼에도 불구하고 KV 캐시 수요는 정체되어 있지 않습니다. 이는 모델 크기에 따라 확장되고 컨텍스트 길이에 따라 선형적으로 증가하며 에이전트 작업 흐름에서는 절대로 재설정되지 않습니다. 이는 다단계 추론 과정 전반에 걸쳐 지속적으로 축적됩니다. 하나의 추론에 10GB 캐시이던 것이 에이전트 상호 작용이 일어날 때마다 누적되는 가변적 대역폭 하한선으로 빠르게 변화합니다.
이는 더 이상 이론적인 이야기가 아닙니다. 다운스트림 네트워크에 진입하는 AI 트래픽은 대역폭이‑높고 급증하며 설계상 항상‑켜져 있습니다. 다운로드가 많고 인간이 주도하는 트래픽 시대에 맞춰 만들어진 WAN은 에이전트형 AI가 생산하는 대칭적이고 기계가 생성하고 지연 시간에 민감한 흐름에 맞도록 설계되지 않았습니다.
네트워크에 반드시 필요한 것
AI 인프라 혁신을 지원하는 데 있어 세 가지 네트워크 아키텍처 대응 방식이 매우 중요해졌습니다.
- 클러스터 내 패브릭 재고(스케일업 및 스케일아웃): 본질적으로 지연 시간에 민감하고 대역폭을 집중적으로 쓰는 AI 학습을 기존의 이더넷으로는 만족시킬 수 없습니다. 이기종 컴퓨팅 노드 간의 무손실 고처리량 연결을 지원하기 위해 모델 구축업체들은 RoCE(RDMA over Converged Ethernet) 및 InfiniBand로 빠르게 갈아탔습니다.
- 클러스터 연결(스케일 어크로스): 분산형 AI 모델 운영을 지원하기 위해 데이터 센터 캠퍼스 또는 지역 간의 무손실 연결을 확장합니다. 여기에는 표준 배포보다 총 용량이 훨씬 큰 전용 코히어런트 광 전송이 필요합니다. 이 새로운 'AI WAN'은 기존 인프라의 점진적인 업그레이드 버전이 아니라 AI 네이티브 트래픽 흐름을 위해 특별한 목적으로 구축된 계층입니다.
- 에이전트를 위한 설계: 리소스와 플랫폼의 동적 통합은 소프트웨어와 하드웨어 간의 격차를 해소해야만 합니다. CPU 집약적인 오케스트레이션 계층과 GPU 집약적인 추론 계층이 분산 인프라 전반에서 함께 작동하기 때문에 지능형 스케줄러, 로드 밸런서, 컴파일러는 비용 모델, 캐시 지역성, 모델 가용성을 지속적으로 모니터링하면서 실시간으로 적합한 하드웨어로 작업 부하를 전송해야 합니다.
우리는 첫 번째 대응이 클러스터 아키텍처에 미치고 앞으로도 미칠 변화의 규모를 이미 경험한 바 있습니다. 두 번째 대응의 영향을 경험했기에 세 번째 대응의 영향도 상상할 수 있습니다.
이는 네트워크에 어떤 의미일까요?
에이전트형 AI가 분산형 AI와 점점 유사해짐에 따라 DC 내부에서 발생하는 이 고대역폭의 급증하고 항상 켜져 있는 대칭형 트래픽은 WAN로 확산될 것입니다. 이는 다음을 의미합니다.
- 컴퓨팅 영역 간의 초선형적 트래픽 증가로 인해 차세대 DCI(데이터 센터 상호 연결)가 필요해짐
- 정적 허브 앤 스포크 네트워크가 확장 상한에 도달함에 따라 에이전트 작업 부하가 패브릭과 같은 동적 연결성이 요구됨
- 작업 부하의 복잡성이 심화되면서 네트워크 자동화가 필수 요소로 변함
결론
균일한 GPU 클러스터의 시대가 저물고 있습니다. 에이전트형 AI는 새로운 인프라 구조를 요구합니다. 앞으로의 인프라 구조에서는 CPU가 클러스터 아키텍처로 복귀해 필수적인 오케스트레이션 엔진으로 사용되고 GPU:CPU 비율이 다단계 AI 작업 흐름의 진정한 복잡성을 반영하며 네트워크가 일차적 성능 결정 요인으로 간주될 것입니다. 서비스 공급자와 엔터프라이즈 입장에서 이러한 변화는 결정적입니다. 분산형 AI용으로 프로그래밍 가능한 고‑용량 기판으로 네트워크를 진화시키는 기업은 에이전트 시대의 중요한 조력자이자 승리자가 될 것이고, 그러지 못하는 기업은 아쉽게도 AI와 그 트래픽이 자신들의 네트워크와 비즈니스를 벗어나 승승장구하는 모습을 지켜보게 될지도 모릅니다.